Performance Evaluation
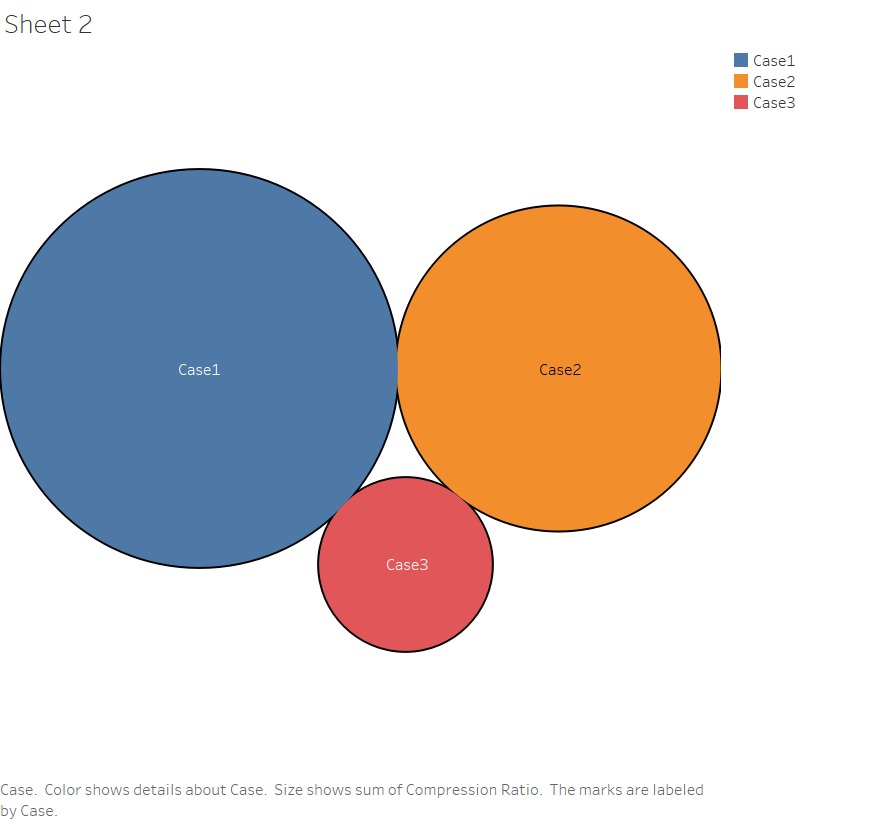
Compression Ratio
The Compression Ratio (CR) is the ratio of size of the summarized text document to
the total size of the original text documents.
CR = |d|/|D|
Where |d| represents the size of the summarized text is document and |D| is the
total size of the original text collection.
Rouge Score: It is used for evaluating the summarization.
ROUGE
ROUGE stands for Recall-Oriented Understudy for Gisting Evaluation, it includes
several measures to quantitatively compare system-generated to human-generated summaries,
counting the number of overlapping n-grams of various lengths, word pairs
and word sequences between the summaries.
In this
work the average precision, recall and F-measure scores generated by ROUGE-1,
ROUGE-2, and ROUGE-L are used to measure the performance of the summaries
The performance parameters of proposed summarizers i.e. compression ratio, ROUGE are evaluated for three different scenarios:
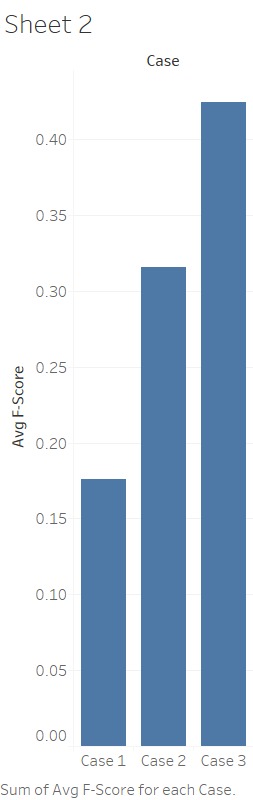
Results of Compression Ratio
It is apparent from the bubble graph below that considering the semantic similarity
(Case 3) will definitely give better results for generating effective and meaningful summary
of text document collections. These results clearly indicates that semantic similarity along
with the clustering gives better summarization results as compared to the summarization
without semantic similarity and clustering.
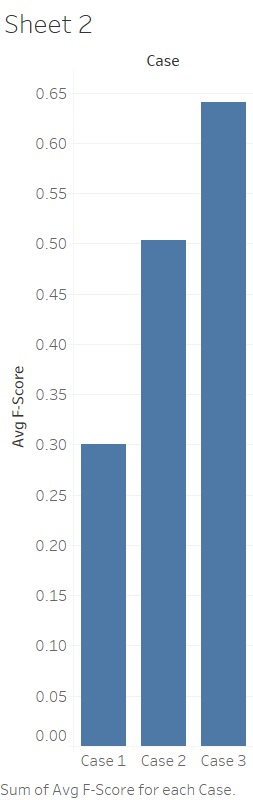
Results of ROUGE Score
As expected from the results, ROUGE scores are found higher for
the case III than the other two cases. Case III consider both the textual similarity (using
clustering) and semantic similarity which makes sure that best summarization content
units participate in the summary generation. Case II gives better results than the Case I
results, in other words summarization using clustering gives better summarization results
as compared to the summarization performed without performing clustering. It
indicates that summarization performed on the clustered text documents is more accurate
since similar text information is grouped within the same clusters.
ROUGE 1
ROUGE 2