System Implementation
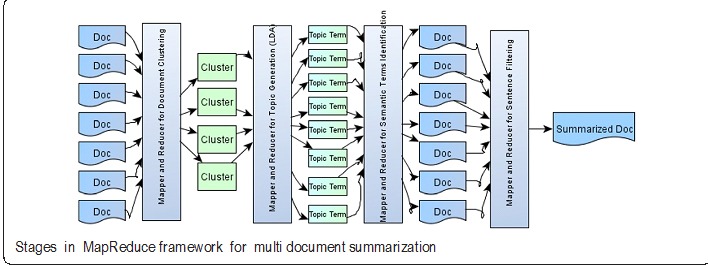
Stages in Multi Document Summarization:
Pre-processing: Dataset is cleaned and pre-processed to convert multiple news articles into vectors.
TFIDF : Multiple news articles are represented in a vector format using information retrieval technique, TFIDF.
K- Means Clustering :
K- Means Clustering technique has been employed on the multi-document text collection to create the text document clusters.

K-Means Details
K- Means Mapper
is responsible for part of documents and part of k centers. For each document,
it finds closest of known centers and produces the output key as point, value
identifies center and distance. K- Means Reducer takes minimum dis- tance center and
produces output key identifies center, value is document. A successive phase
averages points in each center.
Latent Dirichlet Allocation (LDA) : LDA topic modelling technique has been employed on each individual text document cluster to generate the cluster topics and terms belonging to each cluster topic.
LDA Details
After creating the text document clustering, the document belonging to clusters are retrieved and text information present is each document is collected in aggregate. The topic modeling technique is then applied on collective information to generate the topics from each text document clusters. LDA (Latent Dirichlet Allocation) technique is used in this work for generating topics from each document cluster.The implementation is carried using the Java based open source technologies. The LDA implementation is performed using MALLET API.
MALLET is a Java-based package for statistical natural language processing, document classification, clustering, topic modeling, information extraction, and other machine learning applications to text.
Frequent and Semantic terms: Global frequent and semantic terms are generated from the collection of multiple text documents.
Semantic Term Identification
In the third stage, semantic similar terms are computed for each topic term generated in previous stage. WordNet Java API is used to generate the list of semantic similar terms.WordNet® is a large lexical database of English. Nouns, verbs, adjectives and adverbs are grouped into sets of cognitive synonyms (synsets), each expressing a distinct concept. Synsets are interlinked by means of conceptual-semantic and lexical relations.
The Semantic term Mapper computes the semantic similar terms for each topic term generated by the document cluster and Semantic term reducer aggregate these terms and counts the frequencies of these terms (topic terms and semantic similar terms of topic terms) aggregately.
Then the terms are arranged in the descending order of frequency and top N topic terms (including the semantic similar terms) are selected. These filtered terms are called as semantic similar frequent terms available in the document collection
Summarization: For each document, the sentences which are containing the frequent terms and semantic similar terms are selected for participation in the summarized document.
Output of this project is the summarized documents of large News Article collections.
Summarization
In the last stage, the original text document collection is distributed over the Mappers and using parsing techniques, sentences are extracted from individual document by the Mappers. The sentences which are consisting of the frequent terms and its semantic simi- lar terms are filtered from the original text collection and added to the summary docu- ment (in other words the filtered terms participates in the summary document). The final summary is generated after traversing all the documents in the document collections.